Classifiers are very handy general-purpose tools for computing “the degree of connectedness” in relations between observed variables (see this application in marketing).
An example where a classifier is handy to apply, is in data-mining of web-links.
Suppose in this small example that you have the following questions:
- How often is a product from our product line Referred to, among a collection of webpages?
- How often is the Referral due to a link to one of our published images of a product?
- How often is the Referral due to
mentioning of a name of one of our brands?
Classifiers are probability models. So instead of yielding the ‘how often’, they compute the
fraction of occurrences, the fraction of positively Referred pages among all pages in the collection.
In probability terms, we say that we compute the probability:
P(Referral) or in short P(R).
| If 20 out of 100 webpages we visited have referral to one of our products, we say that P(R) = 20/100 = 0.2 |
Until now, we have not used a classifier.
We only computed a probability of referral among a set of webpages which have been screened by a colleague who worked intensively with a web-browser.
I will now show how to build a small classifier.
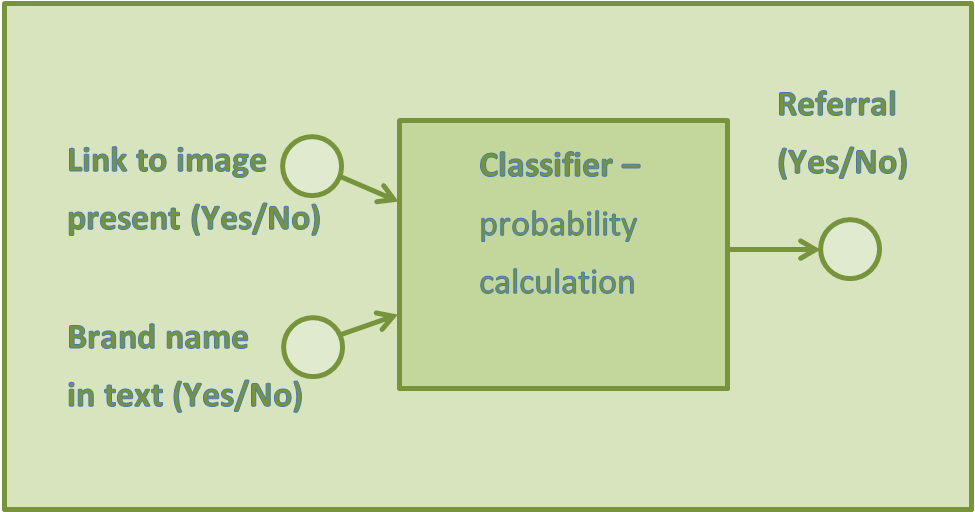
Classifier with two input variables, and one probability outcome. |
Practical computation – answer to your questions
In practice the web is so huge that everybody counts actual number of occurrences of for instance a keyword, and not the fraction of all webpages on our mother earth that refer to the keyword associated with your product line. Well-known browsers yield these numbers.
We begin with a naive perspective on product marketing: every neutral referral to our product is considered a positive referral. So we divide the world of referral-webpages into two groups[1], the ‘positives’ and the ‘negatives’. And you will need to know the number of pages that refer to one of your products.

You are interested in the probabilities:
Oops, something happened. The way of writing the probability became more complex, introducing the ‘|’. This is simply a conditional sign, indicating that given the fact that a webpage makes referral to one of your products, what are the probabilities that the referral is positive or negative?
Let’s assume that the number of positive referrals is 65 out of 100, and the number of negative referral pages is 35 out of the 100 that we visited with our browser.
And because all ‘neutral’ pages were considered positive advertising, the probabilities sum up till 1:
A small classifier
Let’s now focus on only the pages that refer to your product line, and let us leave out the conditional ‘|‘ indicating that we compute only on pages that somehow refer to our product line (still keeping in mind that we compute only with web-pages that do refer).
The probabilities are then written as P(Positive_Referral) and P(Negative_Referral), which sum up till 1.
Now the web-marketing question is whether characterizing positively one of our products is associated with a brand-name, an image-link to one of our products, or both.
| In probability terms, we want to compute the probabilities:
P(Positive_Referral | image_link_present & brand_name_present) P(Positive_Referral | image_link_present & brand_name_absent) P(Positive_Referral | image_link_absent & brand_name_present) P(Positive_Referral | image_link_absent & brand_name_absent) |
and their four opposite probabilities, P(Negative_Referral | image_link_present & brand_name_present),
etc. because
P(Positive_Referral | image_link_present & brand_name_present) +
P(Negative_Referral | image_link_present & brand_name_present) = 1.
What does a high probability say?
P(Positive_Referral | image_link_present & brand_name_present)=0.9
P(Positive_Referral | image_link_present & brand_name_absent)=0.6
Well, that people when referring to our product with both a link to an image of our product and its brand name with great certainty have a positive opinion about the product. Consumers active on the web don’t make the effort to include both links when they want to talk negatively about our product.
What can we do with this knowledge?
Well, our marketing assistant took the effort to manually visit and view 100 webpages somehow referring to our product. In the future, the combined occurrence of an image link and the presence of the brand name is a confident indicator for the amount of positive reputation to our product.
This saves our marketing assistant from visiting thousands of webpages manually, to keep track of how the market reacts to, for example a
new online marketing campaign.
Here comes statistics – how to generalize
Why do we use a probability model to compute relations between variables?
Well, of course you can easily just count numbers of page referrals in a work-sheet
Image absent
Brand name absent
5
Image absent
Brand name absent
5
65 positive referrals |
35 negative referrals |
||||
| Image present | Brand name present | 30 |
Image present | Brand name present | 5 |
| Image present | Brand name absent | 20 | Image present | Brand name absent | 2 |
| Image absent | Brand name present | 10 | Image absent | Brand name present | 23 |
The table above has a hierarchical structure. You can easily enter our findings from visiting say 100 webpages in such a table.
P(Postive_Referral | Image_present & brand_name_present) = (65/ 100 * 30/65) /
((65/100 * 30/65) +
(35/100 * 5/35) ) =0.86
We have now built a classifier!
| The probability P(Postive_Referral | Image_present & brand_name_present) is the actual classification probability, the chance that if we say ‘Postive_Referral’ for a website where a link to our product image is present and our brand name is mentioned, we are right for 86% of those web-pages. |
What you do want is that the entries in the table generalize to all referrals to your product on the whole web – or to other
markets as well. That’s were statistics offers some handy results and formulas.
| Statistics can be seen as a framework that enables us to say – in general – whether some co-occurrence of events – the joint presence of a positive referral, the presence of a specified image-link and a product brand name on a website – is a genuine relation that holds on the large web. |
Does this strong relation, P(Postive_Referral | Image_present & brand_name_present) = 0.86 hold for all pages? Then you have discovered a ‘golden indicator’ for positive referrals to your products.
Statistics uses difficult words to specify (in mathematics) how to draw “certain” [2] conclusions from
statistical data as we collected and displayed in the table above.
Key-terms are: distribution, probability, estimate, confidence interval, mean/average, standard-deviation/variance, sample.
 |
| The histogram above shows the distribution of the probability P(Postive_Referral | Image_present & brand_name_present) over 10.000 runs where all numbers (probabilities) in the table above are computed from randomly drawn samples (with the same probability distribution), each with the size 300.The highest peak is concentrated around the mean 0.86 (the right-interval boundaries are shown on the axis). The distribution is not symmetric over the mean: the left-part below the mean is squeezed compared to the right-part above the mean which is stretched. This distribution is not Gaussian, it’s multivariate binomial. |
You might think, why this graphic?
Can’t we just compute the probabilities from the entries in the table, which we collected from the marketing survey?
One of the many things statistics is good for, is that you can say that the probability P(Postive_Referral | Image_present & brand_name_present) in any survey of size 300 will not be below 0.7, even though your manual survey from 300 websites yielded the probability of 0.86.
Here the tail-probability comes into play:
in less than 0.01 of the samples of size 300, the probability can actually be below 0.7. This is the number of occurrences in the left-most bar in the histogram-graphic.
Distribution
We actually don’t need computer simulations to compute the height of the bins in the histogram – or to compute the number of times a probability will be below for example 0.7 or
0.8.
The most simple case is the probability of a positive referral, 0.65. This probability P(Postive_Referral) is computed as the number of occurrences of a positive referral divided by the number of visited websites: 65/100 = 0.65.
In our simulation, this probability also varies among each sample.
| We know how to draw the graphic for the probability P(Postive_Referral), from the distribution function of the binomial distribution. |
 |
So the probability that we observe 0, 0.01, 0.02,…,1 can be computed directly.
P(67/100) = 100!/(67! (100-67)!) 0.6567 (1-0.65) 100-67 = 0.077.
For the value i=55 further away from the mean 0.65, we get
P(55/100) = 100!/(55! (100-55)!) 0.6555 (1-0.65) 100-55 = 0.01.
| Let us draw the graphic then, from the formula above, for each i: |
 |
| Also this distribution is not symmetric around its mean i=65 (P(Positive Referral=0.65)), it’s Binomial, not Gaussian. |
Why this knowledge is so useful:
Before you present your 3D bar-chart in the meeting room showing the counts in the table above to your colleagues
 |
| The 3D chart showing the data from the table above. The label Ima_PR_Bra_PR indicates that an image-link is present and that a brand name is mentioned. |
it’s so good to know whether the relations you summarize in your conclusions are just random fluctuations, or really indicate some important underlying relations in the marked.
Usage of the classifier – predictions
Now we have built a classifier (mostly the term ‘trained’ is used), and the classifier can be applied to categorize thousands of webpages without manual inspection by the marketing assistant from our example above.
Program a web-crawler (for example in Java) that traverses selected webpages, and the pages that are linked to. Each standard programming book includes source-code for this purpose. The downloaded HTML-document is then scanned for the ‘findings’:
- Our brand name
- A weblink to an image of our product(s)
For each webpage, the web-robot looks for the presence of 1) and 2) and calls the classifier routine, with the findings. If our brand name is present in the document and the image link is also included, we compute the probability:
P(Positive_Referral | Image_present & brand_name_present)
and similarly for another webpage without the image link but with our brand name present, the relevant probability:
P(Positive_Referral | Image_absent & brand_name_present).
| Classification rule:Choose each time the label with the highest probability, given the presence/absence of the two findings. If P(Positive_Referral | Image_present & brand_name_present)>P(Negative_Referral | Image_present & brand_name_present) then ‘Positive referral’ is assumed, otherwise ‘Negative referral’. |
Performance of the classifier
The performance of a classifier can be measured in a number of different ways. The most used performance indicator is the
correctness, the fraction of observations (100 in total in the table above), for which the ‘positive referral’ and ‘negative referral’ are predicted correctly.
| The correctness is defined as. |
 |
For the classifier in the table above, the most likely class is ‘Positive_Referral’ in the two first table rows, and ‘Negative_Referral’ for the third row. For the fourth row, both probabilities are equally likely.
The correctness is computed as follows:
Correctness =P(Positive_Referral | Image_present   &   Brand_name_present) * P(Image_present   &   Brand_name_present)   + P(Positive_Referral | Image_present & Brand_name_absent)   *   P(Image_present   &   Brand_name_absent)   + P(Negative_Referral | Image_absent & Brand_name_present) * P(Image_absent & Brand_name_present) + P(Negative_Referral | Image_absent & Brand_name_ absent) * P(Image_absent & Brand_name_ absent) |
=
0.86 * ( (30+5)/ 100 ) +
0.91 * ( (20+2)/100 ) +
0.70 * ( (10+23)/ 100 ) +
0.50 * ( (5+5)/ 100 ) +
= 0.78
with for example
P(Negative_Referral | Image_absent & Brand_name_ absent) =
(65/ 100 * 5/65) /
((65/100 * 5/65) +
(35/100 * 5/35) ) = 0.50 (the first number in the fourth row).
So for our classifier, we can compute its performance directly.
Variance of correctness – classifier uncertainty
The correctness of the classifier is computed from a set of websites that were analyzed by hand. This limited size of this
training set means that the correctness computed from the classifier in the table above is an estimate. This
is indicated with a circumflex ‘^’ above the correctness.
The standard deviation of the correctness ρ=0.78 (=1-error rate) of this classifier is directly computable, for a given training set. The variance is σ2=0.016 for a training set of size 100. This direct computation is complex, but really useful (Based on the 4 possible training cases).
An introduction to statistical classifiers
A classifier is a mathematical-statistical model that assigns class labels to vectors of variables – patterns – under statistical
uncertainty.
| This means that if you can define an algorithmic decision table – nested if-statements – that categorizes each vector correctly with 100% certainty, this is not a statistical classifier. |
The classifier model begins with a pre-labeled training set and a pre-labeled test set:
X=Training-set = {
Case_1[Feature-1, Feature-2,…,Feature-n;Label-j];Case_2[Feature-1, Feature-2,…,Feature-n;Label-i];
…
Case_N[Feature-1, Feature-2,…,Feature-n;Label-k];
}
with an example case consisting of 5 features being [2,1,1,4,3;2]. This case belongs to class 2. So the training set is a matrix X with the dimension: (N,n+1), with N the number of training cases and n the number of features, plus ‘1’ for the class label.
The test set V is defined similarly. Note the general convention in statistical classification
that the test set is never used to compute model parameters (probabilities) or influence design choices of the classifier.
The test set is reserved till final assessment, computing the correctness/error rate of the classifiers constructed.
The class probability for class j is:
| P(class=j | x1=i ^ x2=k ^…^ xn=h) = P(x1=i ^ x2=k ^…^
xn=h | class=j) P(class=j) /(P(x1=i ^ x2=k ^…^ xn=h | class=1) P(class=1) +P(x1=i ^ x2=k ^…^ xn=h | class=2) P(class=2) +…P(x1=i ^ x2=k ^…^ xn=h | class=c) P(class=c)) |
The apparent problem that appears is that when m features are added to the classifier, is that the possible number of
probabilities increases with the product of the dimensions of the m additional features.
Take as example n=4 binary features which equals 2*2*2*2 = 16 possible outcome vectors. Now, add 2 features each with 4 outcomes, and the number of combinations becomes 16*4*4=256 outcomes, an increase with a factor 16!
What is the problem here?
The most rare feature-value combinations may in a medium-sized training set have the probabability 0, because they don’t occur. Hence, our classifier does for these cases not yield a probability, but a 0/1 answer, which is unreliable! This holds especially for the most rare feature combinations.
Another problem with this exponential increase in the number of dimensions is the amount of computer memory needed. Imagine to represent for example 40 binary features, with in total 2^40=1,09951E+12 possible outcomes. Reserving one byte per possible feature outcome (not accounting for each double-valued probability), entails 1024 Gb of memory.
It’s not the problem to declare a 40-dimensional array, neigther to use the 40-dimimensional index vector to retrieve the probabilities. The real problem is that the probabilities are highly uncertain – and often zero – unless the size of the training set becomes really large.
To counter-weigh this problem, the so-called naïve classifier is introduced.
Write
P(x1=i ^ x2=k ^…^
xn=h | class=j)
as
P(x1=i ^ x2=k ^…^
xn=h | class=j) =
P(x1=i | class=j) *
P(x2=k | class=j) *
… *
P(xn=h | class=j)
| The assumption made is that all the n features are independent, within each class. This assumption in most cases does not hold, but naïve classifiers often yield surprisingly good performance (correctness) when the number of features n is large. The performance criterion that counts, is the correctness on the test set V. |
The uncertainty of the probabilities P(x1=i | class=j) is very much smaller than for the full-probability classifier. But, the class-probabilities are generally biased (unless the independence assumption is valid). It is by the way easy to test whether the assumption of independence is valid for the features.
Notes:
[1] Classifiers can distinguish between as many groups (classes) as you like.
[2] All conclusions yield uncertain answers, but a sustained conclusion with a probability>0.999, may in practical everyday reasoning be considered certain, given that the underlying model-assumptions are fulfilled, (0.999999 gives even more certainty).
The fancy market figures ensure a confident margin in our growth market.The rising star markets show a profitable and sustained growth. |
This is convincing at the sales meeting – I even added that statistics is sexy –
the confidence interval of the table counts gives the solid proof.
What a flashy chart.
看中的市场数字,确保在我们的成长市场的信心保证金。
冉冉升起的明星市场,显示出盈利和持续增长。
这是在销售说服满足表计数的置信区间,给出了确凿的证据。什么华而不实图表。